Content Representation¶
Turning archival items into machine-usable content: structured, connected through a Knowledge Graph, and embedded so the engine can reason about meaning, not just text.
A memorial archive holds rich human artifacts: diaries, testimonies, photographs, artworks, maps, audio and video. To software they start as opaque material with only basic metadata and few links between them. This area builds three complementary views so the engine can find content by knowledge and by resonance, and explain why:
- Structure: title, text, media, place, time. The plain facts.
- Knowledge: items connected through people, places, and events, using a shared ontology and the WO2 and VHA controlled vocabularies.
- Meaning: a numeric fingerprint of what an item is about, so items on the same theme sit close together even when their words differ.
What you will find here¶
-
HNP corpora and Knowledge Graph
The raw multimodal corpus and how NER plus entity linking turn it into a structured graph.
-
The semantic space where proximity means similar meaning, and the encoders that build it.
-
Where embeddings and metadata live together for fast, filtered, geospatial retrieval.
-
BERTopic clusters that give first-time visitors meaningful entry points.
-
The curated source of truth and how items are pulled into the pipeline.
API for this area
Content is written into the store by the content-engine service. See the interactive
Content Manager API (POST /ingest, POST /sync/omeka).
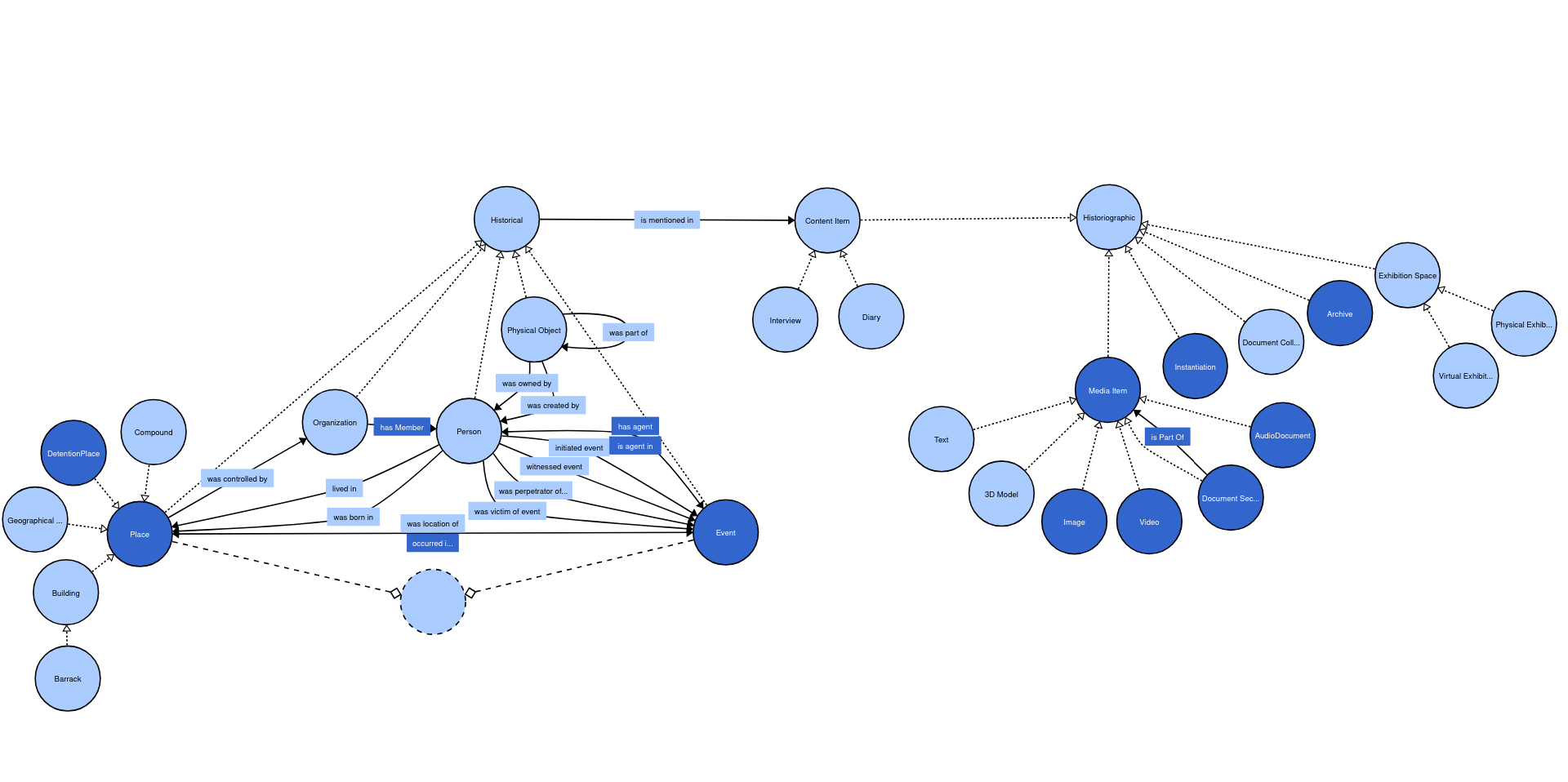
The MEMORISE ontology: historical classes (Person, Place, Event, Object) and historiographic classes (Document, Media Item, Archive) that connect fragmented sources into one graph.