Topic Discovery (Cold Start)¶
How the system offers meaningful entry points to a visitor before any interaction history exists.
A brand new visitor is a blank slate: no clicks, no dwell, no taste vector. Asking them to browse arbitrary items is a poor welcome, especially in a large, emotionally heavy corpus. Topic discovery solves this by finding the natural themes already present in the collection and presenting them as a structured map: clusters such as "life in ghettos", "liberation", or "family correspondence" that a visitor can pick from as intuitive starting points.
These themes are not hand-defined. They emerge directly from the content, which keeps the map honest to what the archive actually holds, and complements the curated, precise structure of the Knowledge Graph with flexible, discovered structure.
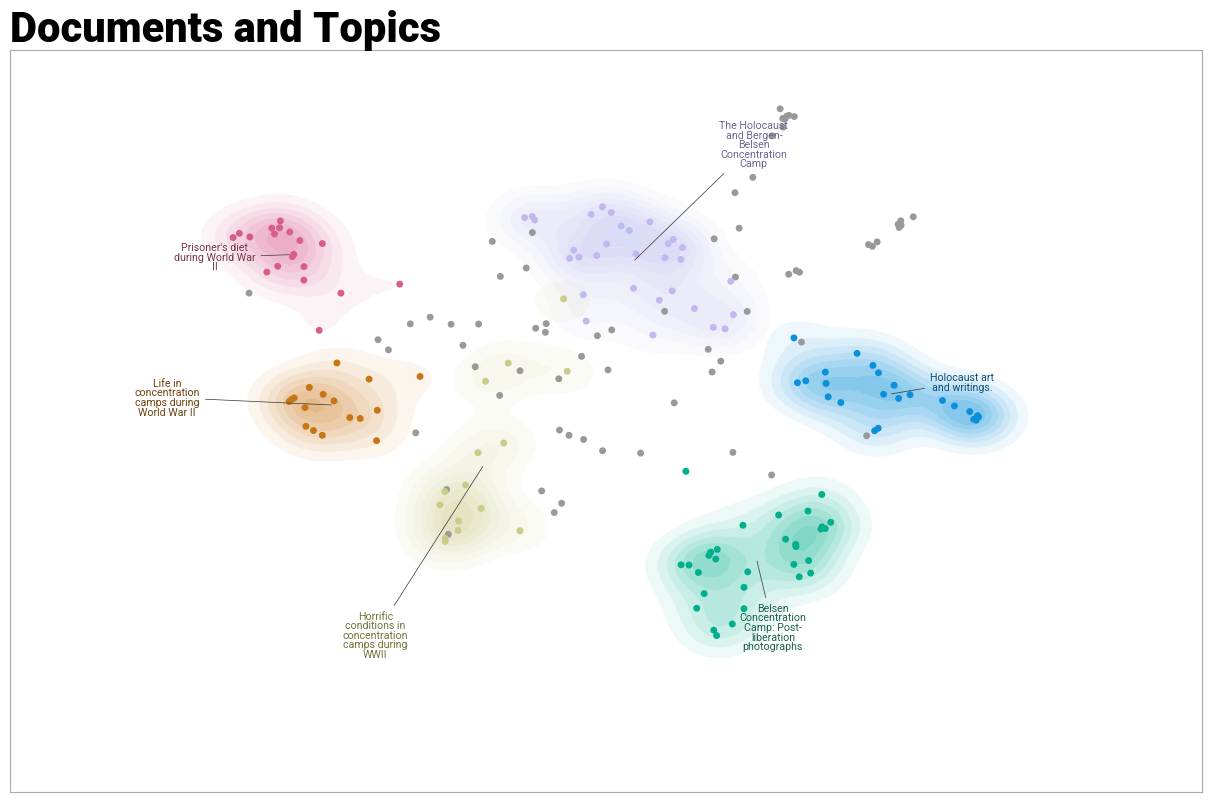
Unsupervised topic clusters over the collection. Each group shares a theme (prisoner's diet, life in the camps, post-liberation photographs), giving cold-start visitors a map to start from.
The clusters are produced with BERTopic, which combines transformer embeddings with clustering. Four stages:
flowchart LR
items["Omeka items"] --> e["1. Embed<br/>(sentence transformers)"]
e --> u["2. Reduce<br/>(UMAP)"]
u --> c["3. Cluster<br/>(HDBSCAN)"]
c --> l["4. Label<br/>(class-based TF-IDF + LLM)"]
l --> topics["topic clusters"]- Embed: items become semantic vectors via pre-trained sentence transformers.
- Reduce: UMAP projects vectors to lower dimensions, preserving semantic neighbourhoods and improving clustering.
- Cluster: HDBSCAN groups items, detecting clusters of varying size and leaving outliers unassigned.
- Label: class-based TF-IDF extracts representative keywords per cluster (for example "deportation, train, transport, arrival, camp"); an LLM can turn these into natural-language labels.
The resulting topics extend content representation three ways: entry points for new users, metadata enrichment where annotations are incomplete, and hybrid queries in Qdrant such as "find testimonies related to Topic X within a given time and place." Topic labels are stored alongside embeddings.
In the engine this is the Reactive layer's cold-start seeding (see
DAC architecture). The working topic data lives in
static/data/topics.jsonl and is surfaced as the 2D scatter on the demo Explore page.