Behavioral Model¶
Turning a stream of events into the dynamic half of the digital twin: inferred states, derived interests, and a vector that captures taste.
Raw events on their own are not interest. A click is just a click. The behavioral model reads many events together and infers higher level things:
- User states: is the visitor engaged, losing attention, frustrated? Estimated from patterns like average dwell per topic, frequency of returns, and session length.
- Interests: which themes and people the visitor keeps coming back to, read from navigation and dwell.
- A taste direction: a single point in meaning space that summarises everything the visitor has responded well to, so the engine can ask for more content near it.
A visitor's search text is also a rich source. A query like "testimonies from Bergen-Belsen in 1944 about Elliot Anderson" carries an intent (find information), entities (a person, a place), and a time scope (1944). Reading that structure out of plain language gives the model context that behavior alone cannot.
State estimation. Implicit indicators (dwell, scroll depth, returns, drop-off) and explicit ones (ratings, saves) are processed by the Adaptive layer into engagement, attention, satisfaction, and frustration, as defined in D5.1.
Behavioral embedding. The interest vector is a time decayed centroid of the embeddings of items the visitor engaged with:
where the \(i_k\) are previously engaged items, \(f_\theta\) is the content embedding (see Vector embeddings), and \(w_k\) weights each item by recency, dwell, and explicit feedback. This vector is the query for semantic recall, and it evolves as the session goes on.
Intent parsing. Search prompts (and, where appropriate, conversational input) are
parsed with an LLM into structured JSON: inferred intent (find_information, compare,
explore), topical focus, entities (names, places, dates), and constraints (media type,
time window). The parsed output is stored and used as context for ranking.
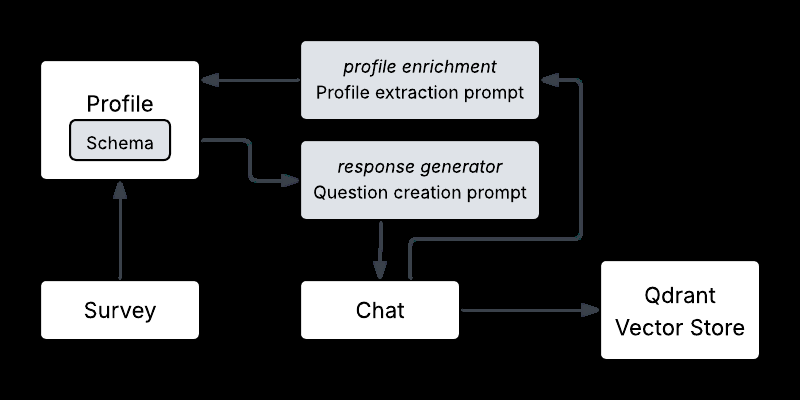
User model enrichment: a survey seeds the profile, then search and conversational input are parsed by an LLM to enrich it, and the result is persisted to the vector store.
flowchart LR
survey["Survey"] --> profile["Profile schema"]
chat["Search / chat"] --> enrich["profile extraction<br/>(LLM prompt)"]
enrich --> profile
profile --> qd[("Qdrant vector store")]
classDef st fill:#EFEAE0,stroke:#A8895B,color:#423D34;
class qd st;Storage. Static attributes (demographics, persona, explicit preferences) are stable and live in a relational database. Dynamic signals are first persisted as raw events for completeness and reprocessing, then compacted into features and vectors stored in Qdrant for fast similarity search and real time adaptation.
The code-level fold (engagement scoring, decay, taste vector, tag affinity) is documented
in Signals. The note on continuous vs binary engagement and the
UserSignals model are in Contracts and models.
Math rendering
The behavioral embedding formula uses LaTeX. If it does not render, the docs need the MathJax extension enabled; the formula reads: u equals the normalized weighted sum of engaged-item embeddings.